Title here
Summary here
以 GPT 为首的闭源 LLM 已经非常优秀了,那么我们为什么还需要一个本地的 LLM 呢?我的答案是需要的。
目前,AI 发展的方向是朝着 AGI 的方向发展:
(Artificial General Intelligence): 是指能够执行任何人类智能任务的机器智能,是一种理论上的AI形式,目前还未实现。AGI与目前普遍存在的专用或窄AI(ANI)不同,后者只能在特定任务上表现出智能。
但是就目前的研究表明,AI 目前还不具备真正的智能:https://time.com/collection/time100-voices/6980134/ai-llm-not-sentient/
我们先不讨论 AGI 未来能不能实现,就目前而已,LLM 远没有我们想象中那么强大,入门的文章也说了,你以为的 AI 跟你想象中的 AI,还有很长的一段距离要走:
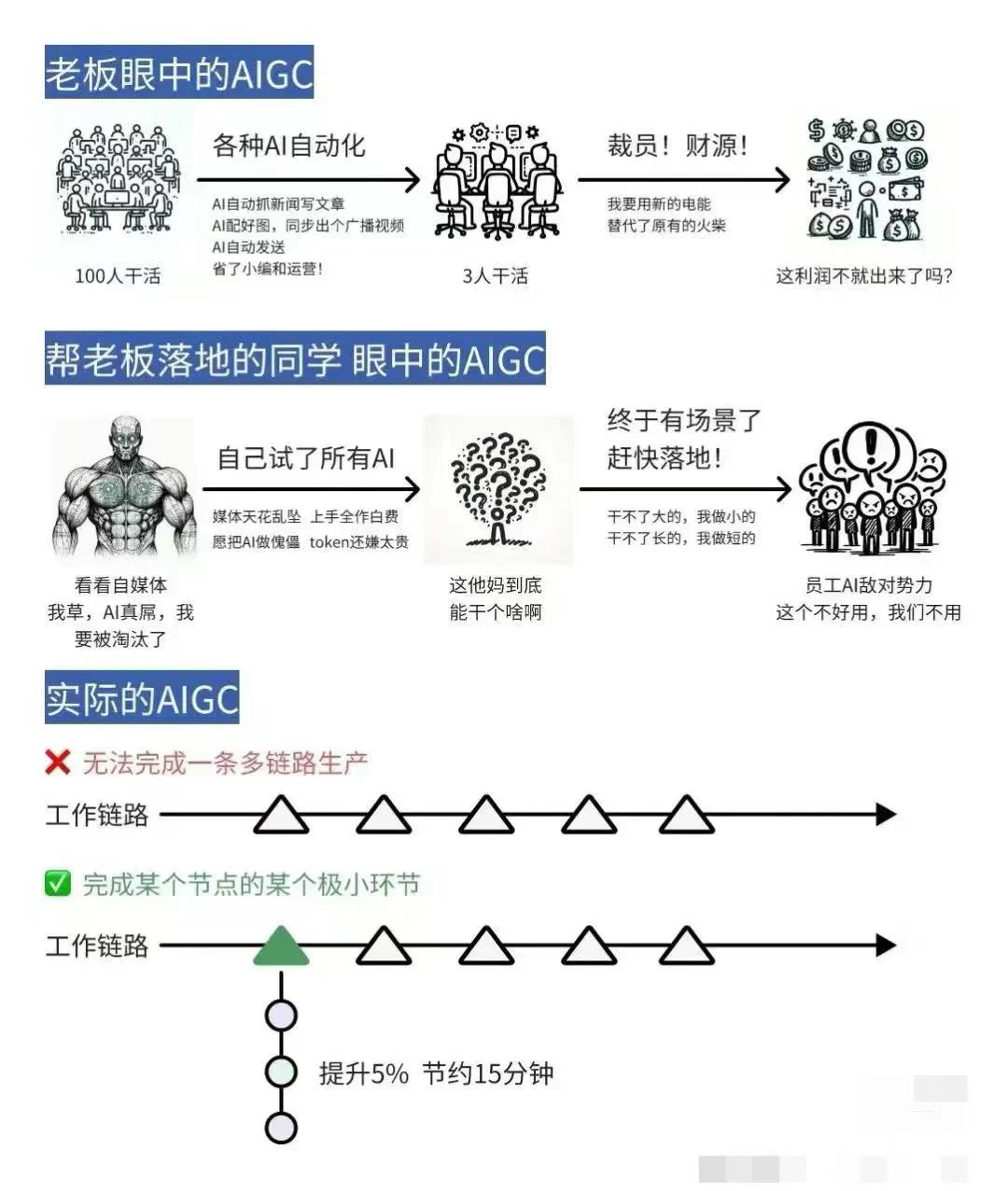
回到我们的问题:为什么我们需要本地的大模型?因为现有的云端 LLM 大模型还有很多问题,也没有足够的智能,从而我们需要不同的大模型来满足不同的需求。
比如目前专有领域的模型有:
可以看到,每个专有的模型擅长的领域都不太一样,对比目前全球地表最强的 GPT4o 模型,在某些领域其实也要甘拜下风。所以当云 LLM
满足不了需求的时候,就需要
这些专有大模型进行补充。
那这些专有大模型仍然可以部署在云端,为啥还需要本地大模型呢?原因如下:
综上所述,在实际的AIGC 生成过程中,仍然需要借助本地 LLM 来完成。
能支持本地的大模型框架也比较多,目前比较好用,受用比较广的有:vllm ,chatglm.cpp, LM studio,Ollama, 他们各自的特点如下:
| Ollama | vllm | chatglm.cpp | LM studio | |
|---|---|---|---|---|
| 功能特点 | 简单易用,本地化 | 推理加速 | C++优化性能,多平台 | 简化操作,本地化 |
| 操作系统 | 多平台 | 多平台 | 多平台 | 多平台 |
| 硬件要求 | GPU/CPU | GPU | GPU/CPU | GPU/CPU |
| 易用程度 | 5 | 4 | 4 | 4.5 |
| Docker | 支持 | 支持 | 支持 | 不支持 |
| 使用场景 | 开发/验证/非技术人员 | 开发 | 开发 | 开发/验证/非技术人员 |
个人:我推荐使用国内的免费的服务器:Vercel 这个网站提供了免费的部署资源,对个人非常友好,我的当前博客网站,就是在上面托管的
企业:企业可以通过购买腾讯云,阿里云,或者是 Azure 云等等方式来进行部署
进入到官网, 点击下载,选择自己的平台: https://ollama.com/
我这里选择 linux 平台,因为是在我购买的服务器进行的,windows 与 mac 更简单,这里就不再演示了。
执行:
curl -fsSL https://ollama.com/install.sh | sh等待下载中:

下载完成之后会自动启动运行的,我们看到这个就说明成功启动了:
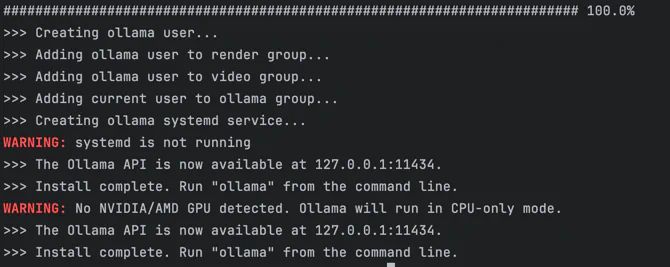
Ollama 启动之后,并不能直接使用,因为里面还没有模型。
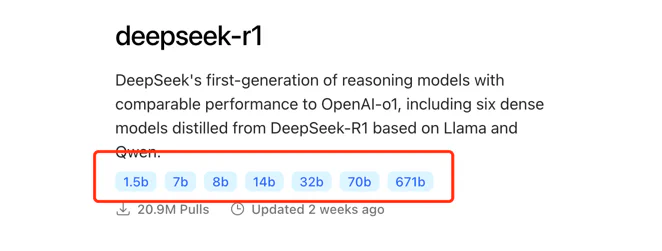
模型地址:https://ollama.com/search ,以现在最火的 DeepSeek-R1 为例,链接为:https://ollama.com/library/deepseek-r1
里面有各种不同的量化参数,大家经常说得满血版本,就是 671b 参数的,但是这个对硬件要求特别高,我们通常用 1.5b 或者 7b 的,大家根据
自己的硬件条件,下载不同的模型, 我这边下载的是 7b 的:
注意下载的时间比较长,大家可能开个梯子比较快:
ollama run deepseek-r1:7b
下载之后,直接在当前窗口就可以对话了
当前窗口对话,效果很差,我们可以使用一些 webui 来优化,比如这个:https://github.com/open-webui/open-webui
open-webui 提供了一个 web 页面,兼容 openai 与 ollama,我们可以直接在上面对话,安装上面的教程部署好之后,打开对应的地址,就可以直接对话了:

由于这篇文章主要讲的是 ollama 的部署过程,就不展开详细讲解如何部署 open-webui,大家可以自己看链接里的部署说明,或者是网上的相关教程。
Ollama 的部署相对来说比较简单,对新手小白来说都比较友好。另外很多人没有稳定的 openai 账号,所以无法直接使用 openai 的 api 进行请求, 部署一个本地的大模型就有必要了。
总之大家要根据自己的资源与需求,选择合适的大模型。
#
学习LLM & 讨论AIGC #

每天大模型、LLM、AIGC 技术咨询